"Scaling Distributed Machine Learning with the Parameter Server"
Problem to solve
Build a parameter server framework for distributed machine learning problems.
Challenges
machine learning model has \(10^9\) to \(10^{12}\) shared parameters that need to frequently access
- High network bandwidth requirement
- Synchronization cost and high machine latency can hurt model performance
- Fault tolerance is critical
Design assumptions
- Machine learning algorithms are quite tolerant to perturbations
- Machine learning algorithms can be thought of consisting data + parameters
Design
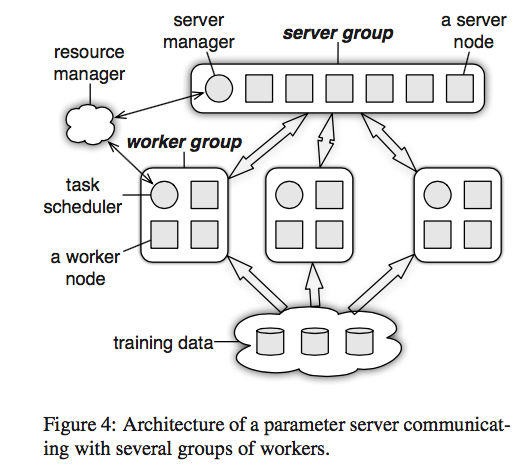
-
Use a group of parameter servers
- can all serve one algorithm to have high availability
- can also run more than one algorithm simultaneously
-
A server node in the server group maintains a partition of the globally shared parameters.
Note
Partition might be a bad idea from fault tolearance and availability perspectives (the two main purposes behind doing replication). By doing partition, we can reduce the workload on each server but we still effectively use one server to serve a set of parameters, which makes the server group idea meaningless. In other words, we want to use several servers to serve the same set of parameters to increase fault tolerance and availability.
-
Parameter servers in the server group partition keys using consistent hashing with virtual nodes (See Dynamo Paper for details).
- Virtual nodes adv: improve load balancing & recovery
- Consistent hashing adv: failure locality (only three nodes are affected)
-
Live replication of parameters between servers supports hot failover
-
The communication of parameter updates and processing are batched to reduce network overhead (e.g. send a segment of a vector or entire row of matrix)
-
The communication is also compressed to reduce network usage
-
Parameters are stored using (key, value) vectors to facilitate linear algebra operations
-
Tasks are executed asynchronously: the caller can perform further computation immediately after issuing a task.
-
Flexible consistency: training iterations vs. throughput tradeoff
- Eventual consistency: all tasks may be started simultaneously. Highest throughput (i.e., system efficiency) but the algorithm may take more iterations to converge because the update may be on stale parameters. Thus, eventual consistency model is recommended for algorithms that are agnostic to delayed parameter value.
- Sequential consistency: all tasks are executed one by one. Lowest throughput but all parameters are guaranteed to be latest.
- Bounded Delay: consistency model between sequential consistency and eventual consistency.
-
Server node are replicated after aggregation to reduce network usage
-
Worker crash: we don’t recover the worker node because:
- when training data is large, recover worker node is very expensive
- Losing a small amount of training data during optimization affects the model a little
-
We can spawn new task if one of machnies appear to be slow (to handle straggler problem)
Remarks
- Worker nodes may need to access the auxiliary metadata. In design, we always need to think of using metadata.
- A server manager node maintains a consistent view of the metadata of the servers, such as node liveness and the assignment of parameter partitions. This is the place to use Paxos.
Note
Paxos can also be used when we have small set of parameter servers. Their membership can be stored using Paxos. Usually, paxos cannot scale over 5 servers.
- Machine learning algorithm tolerates stale data is the major point we exploit when design “Big data + ML” system