"Dynamo: Amazon’s Highly Available Key-value Store"
Problem, Motivation
- How to build a highly available (i.e. reliability) and scalable distributed key-value storage system?
System Assumptions and Requirements
-
Query Model: simple KV store operations: read & write
- store small objects (<= 1 MB)
- no operations span multiple data items; no need for relational schema
-
ACID properties: trade consistency in ACID for high availability
- no isolation guarantees
- permits only single key updates
-
Efficiency: commodity machines; stringent latency requirements specified by SLAs
- SLA (Sevice Level Agreement): a contract where a client and a service agree on several system-related characteristics: client’s expected request rate distribution for a particular API, the expected service latency under those conditions, etc.
- Dynamo:
- SLAs measured at the 99.9th percentile of the distribution (e.g., a response within 300ms for 99.9% of its requests for a peak client load of 500 requests per second)
- configurable: to meet service latency & throughput requirements
Note
- Dynamo is an AP system
- Measuring tail latency instead of average latency is because Dynamo wants to optimize the worst case scenario. In the system is designed for the common usage situations, average latency is a fine measurement.
Design Considerations
-
Strong consistency and high data availability cannot be achieved simultaneously
- Dynamo sacrifice strong consistency: Dynamo is designed to be an eventually consistent data store; that is all updates reach all replicas eventually.
-
Increase availability for system prone to server and network failures: Optimistic replication techniques
- changes are allowed to propagate to replicas in the background, and concurrent, disconnected work is tolerated.
- Conflicts must be detected and reolved:
- When (whether conflicts should be resolved during reads or writes?):
- Dynamo: resolved when read; writes are never rejected
- Who (who performs the process of conflict resolution: data store or application?):
- Dynamo: the application; data store implements a simple policy (i.e., “last write wins”)
- When (whether conflicts should be resolved during reads or writes?):
-
Incremental scalability: scale out one storage host (node) at a time with minimal impact
- Symmetry: every node in Dynamo should have the same set of responsibilities as its peers (i.e., no special nodes)
- Decentralization: design favors decentralized peer-to-peer techniques
- Heterogeneity: system needs to be able to exploit heterogeneity in the infrastructure it runs on (e.g. the work distribution must be proportional to the capabilities of the individual servers)
Design Requirement
- “Always writeable”: no updates are rejected due to failures or concurrent writes
- All nodes are assumed to be trusted
- No support for hierarchical namespaces (a norm in many file systems) or complex relational schema
- Built for latency sensitvie applications: at least 99.9% of read and write operations to be performed within a few hundred milliseconds
Architecture
Note
The architecture of a storage system in a production setting needs to include:
- actual data persistence component
- load balancing
- membership and failure detection
- failure recovery
- replica synchronization
- overload handling
- state transfer
- concurrency and job scheduling
- request marshalling
- request routing
- system monitoring and alarming
- configuration management
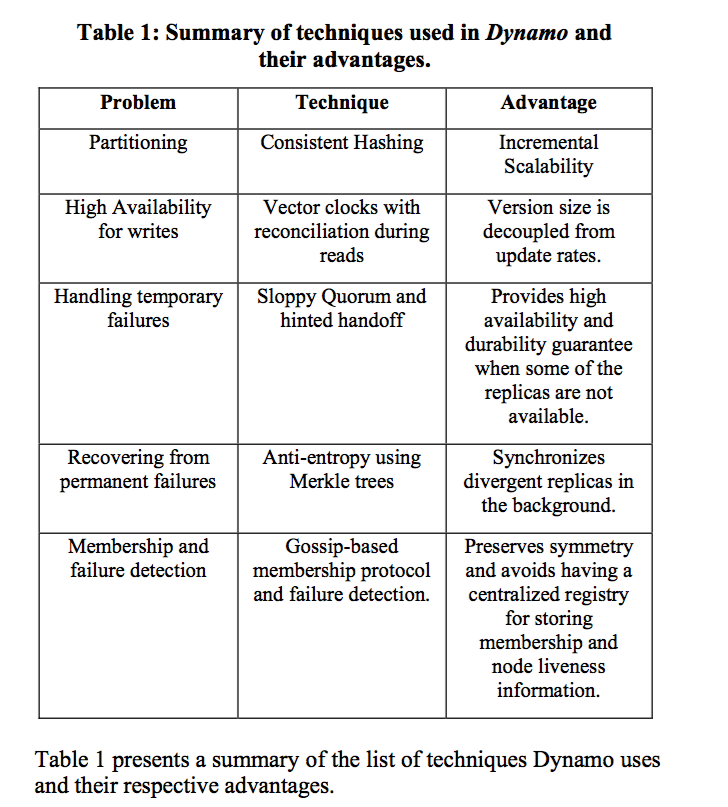
Note
The relation between Table 1 entry and the following sections:
- Partitioning (Partitioning Algorithm, Replication)
- High Availability for writes (Data Versioning)
- Handling temporary failures (Execution of get () and put () operations, Handling temporary failures: Hinted Handoff)
- Recovering from permanent failures (Handling permanent failures: Replica synchronization)
Partitioning Algorithm
-
Dynamo’s partitioning scheme relies on consistent hashing to distribute the load across multiple storage hosts (i.e., nodes).
-
Consistent hashing:
the output range of a hash function is treated as a fixed circular space or “ring” (i.e. the largest hash value wraps around to the smallest hash value). Each node in the system is assigned a random value within this space which represents its “position” on the ring. Each data item identified by a key is assigned to a node by hashing the data item’s key to yield its position on the ring, and then walking the ring clockwise to find the first node with a position larger than the item’s position. Thus, each node becomes responsible for the region in the ring between it and its predecessor node on the ring.
-
Pro & Cons of consistent hashing:
- Pro:
- departure or arrival of a node only affects its immediate neighbors and other nodes remain unaffected
- Cons:
- the random position assignment of each node on the ring leads to non-uniform data and load distribution
- The basic algorithm is oblivious to the heterogeneity in the performance of nodes (i.e., some node may have a more powerful setup but consistent hashing treat it the same as others)
- Pro:
-
Dynamo uses a variant of consistent hashing:
Instead of mapping a node to a single point in the circle, each node gets assigned to multiple points in the ring. To this end, Dynamo uses the concept of “virtual nodes”. A virtual node looks like a single node in the system, but each node can be responsible for more than one virtual node. Effectively, when a new node is added to the system, it is assigned multiple positions (i.e., “tokens”) in the ring.
-
Advantages of using virtual nodes:
- If a node becomes unavailable (due to failures or routine maintenance), the load handled by this node is evenly dispersed across the remaining available nodes
- When a node becomes available again, or a new node is added to the system, the newly available node accepts a roughly equivalent amount of load from each of the other available nodes
- The number of virtual nodes that a node is responsible can decided based on its capacity, accounting for heterogeneity in the physical infrastructure
Replication
-
To achieve high availability and durability, Dynamo replicates its data on multiple hosts.
Each data item is replicated at N hosts, where N is a parameter configured “per-instance”. Each key, k, is assigned to a coordinator node (the node that a key is assigned to in consistent hashing; the first among the top N nodes in the preference list). The coordinator is in charge of the replication of the data items that fall within its range. In addition to locally storing each key within its range, the coordinator replicates these keys at the N-1 clockwise successor nodes in the ring. This results in a system where each node is responsible for the region of the ring between it and its Nth predecessor.
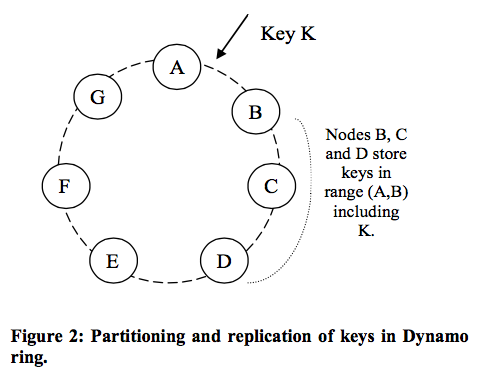
Example: node B replicates the key k at nodes C and D in addition to storing it locally. Node D will store the keys that fall in the ranges (A, B], (B, C], and (C, D].
The list of nodes that is responsible for storing a particular key is called the preference list. Every node in the system can determine which nodes should be in this list for any particular key. To account for node failures, preference list contains more than N nodes. The preference list for a key is constructed by skipping positions in the ring to ensure that the list contains only distinct physical nodes (first N virtual nodes may all be hosted by one physical node).
Data Versioning
- Dynamo provides eventual consistency, which allows for updates to be propagated to all replicas asynchronously.
- Dynamo allows multiple versions of the same object but if reconcilation fails, the client must perform the reconciliation in order to collapse multiple branches of data evolution back into one (semantic reconciliation).
Note
Works like Git: if Git can merge different modifications into one, Git is done automatically for you. If not, you (client) have to manually reconcile conflicts.
- Dynamo uses vector clocks in order to capture causality between different versions of the same object.
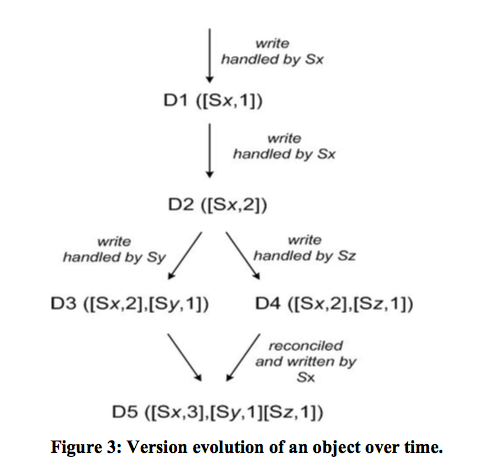
Note
Each object (e.g., D5) contains a vector clock (e.g., ([Sx,3],[Sy,1],[Sz,1])). Note that it is not a list of vector clocks.
You can think about Sx, Sy, Sz as process names to map to the original vector clock example.
- Dynamo uses a clock truncation scheme to control the size of vector clocks
Execution of get () and put () operations
- Any storage node in Dynamo is eligible to receive client get and put operations for any key
- Read and write operations involve the first N healthy nodes in the preference list, skipping over those that are down or inaccessible (remember preference list contains more than N nodes).
-
To maintain consistency among its replicas, Dynamo uses a consistency protocol similar to those used in quorum systems.
This protocol has two key configurable values: R and W. R is the minimum number of nodes that must participate in a successful read operation. W is the minimum number of nodes that must participate in a successful write operation. Setting R and W such that R + W > N yields a quorum-like system. In this model, the latency of a get (or put) operation is dictated by the slowest of the R (or W) replicas. For this reason, R and W are usually configured to be less than N, to provide better latency.
Note
Dynamo client applications can tune the values of N, R and W to achieve their desired levels of performance, availability and durability:
- N determines the durability of each object
-
The values of W and R impact object availability, durability and consistency
- If W is set to 1, then the system will never reject a write request as long as there is at least one node in the system that can successfully process a write request
- low values of W and R can increase the risk of inconsistency as write requests are deemed successful and returned to the clients even if they are not processed by a majority of the replicas; This also introduces a vulnerability window for durability when a write request is successfully returned to the client even though it has been persisted at only a small number of nodes.
-
Execution of put() operation:
- Coordinator generates the vector clock for the new version
- Coordinator writes the new version locally
- Coordinator sends the new version + vector clock to the N highest-ranked reachable nodes
- If at least W-1 nodes respond then the write is considered successful.
-
Execution of get() operation:
- Coordinator requests all existing versions of data for that key from the N highest-ranked reachable nodes in the preference list for that key
- Coordinator waits for R responses before returning the result to the client
- Reconcilation done by the applications is written back
Handling temporary failures: Hinted Handoff
-
Cons of traditional quorum approach:
Unavailable during server failures and network partitions and durability reduced under the simplest of failure conditions
-
Doesn’t strict quorum membership and use “sloppy quorum”:
all read and write operations are performed on the first N healthy nodes from the preference list, which may not always be the first N nodes encountered while walking the consistent hashing ring.
-
Hinted Handoff:
Consider the example of Dynamo configuration given in Figure 2 with N=3. In this example, if node A is temporarily down or unreachable during a write operation then a replica that would normally have lived on A will now be sent to node D. This is done to maintain the desired availability and durability guarantees. The replica sent to D will have a hint in its metadata that suggests which node was the intended recipient of the replica (in this case A). Nodes that receive hinted replicas will keep them in a separate local database that is scanned periodically. Upon detecting that A has recovered, D will attempt to deliver the replica to A. Once the transfer succeeds, D may delete the object from its local store without decreasing the total number of replicas in the system.
-
Using hinted handoff, Dynamo ensures that the read and write operations are not failed due to temporary node or network failures.
Handling permanent failures: Replica synchronization
- Dynamo implements an anti-entropy (replica synchronization) protocol to keep the replicas synchronized.
-
To detect the inconsistencies between replicas faster and to minimize the amount of transferred data, Dynamo uses Merkle trees:
A Merkle tree is a hash tree where leaves are hashes of the values of individual keys. Parent nodes higher in the tree are hashes of their respective children. The principal advantage of Merkle tree is that each branch of the tree can be checked independently without requiring nodes to download the entire tree or the entire data set. Moreover, Merkle trees help in reducing the amount of data that needs to be transferred while checking for inconsistencies among replicas. For instance, if the hash values of the root of two trees are equal, then the values of the leaf nodes in the tree are equal and the nodes require no synchronization. If not, it implies that the values of some replicas are different. In such cases, the nodes may exchange the hash values of children and the process continues until it reaches the leaves of the trees, at which point the hosts can identify the keys that are “out of sync”. Merkle trees minimize the amount of data that needs to be transferred for synchronization and reduce the number of disk reads performed during the anti-entropy process.
Membership and Failure Detection
-
Use explicit command to add and remove nodes from a Dynamo Ring:
- Adv: nodes may be temporarily down and we don’t have to immediately redistribute workload (i.e., think they are out of ring membership) whenever some node are uncontactable. Redistribute workload is expensive.
-
To prevent logical partitions, some Dynamo nodes play the role of seeds:
- Case: node A joins the ring; node B joins the ring; but A and B would consider each other be the member of the ring at once
- Seeds are nodes that are discovered via an external mechanism and are known to all nodes.
- Typically seeds are fully functional nodes in the Dynamo ring.
- Because all nodes eventually reconcile their membership with a seed, logical partitions are highly unlikely.
-
node A may consider node B failed if node B does not respond to node A’s messages (even if B is responsive to node C’s messages)
Decentralized failure detection protocols use a simple gossip-style protocol that enable each node in the system to learn about the arrival (or departure) of other nodes.
Remarks & Thoughts
I really like this paper. It connects all the classic distributed techniques (i.e., gossip, quorum, consistent hashing, merkle tree) into one.
Further Readings
- Some views from peers CS 739 Reviews - Fall 2014, CS 739 Reviews - Spring 2012