"Fast Crash Recovery in RAMCloud"
Problem, Motivation
RAMCloud is a large-scale general-purpose DRAM storage system for datacenters. The system is motivated by the fact that Large-scale apps struggle with utilizing DRAM to its full potential:
- DRAM is still majorly used as a cache for some other storage system
- Developers have to manage consistency between caches in DRAM and its storage system
- Cache misses and backing store overheads
It has four design goals:
- Scalbility: 1000-10000 commodity servers with 32-64 GB DRAM/server
- Low latency: uniform low-latency access (5-10 μs round-trip times for small read operations)
- High throughput: 1M ops/sec/server
- High durability and availability
This paper focuses on the “high durability and availability”. Replicating all data (x3) in DRAM fix some availability issue but triple the cost and energy usage of the system. Thus, RAMCloud only stores a single copy of data in DRAM, which brings the problem of availability: what happens when server crashes? RAMCloud’s solution to the availability problem is fast crash recovery. Then the problem becomes how to recover from crash within 1s~2s for 64GB or more DRAM data?
Challenges
- Durability: RAM is lack of durability. Data is unavailable on crashed nodes.
-
Availability: How to recover as soon as possible?
- Fast writes: Synchronous disk I/O’s during writes?? Too slow
- Fast crash recovery: Data unavailable after crashes?? No!
-
Large scale: 10,000 nodes, 100TB to 1PB
Assumptions
-
Use low-latency Infiniband NICs and switches
- Ethernet switches and NICs typically add at least 200-500 μs to round-trip latency in a large datacenter
-
DRAM uses an auxiliary power source
- to ensure that buffers can be written to stable storage after a power failure
-
Every byte of data is in DRAM
Architecture
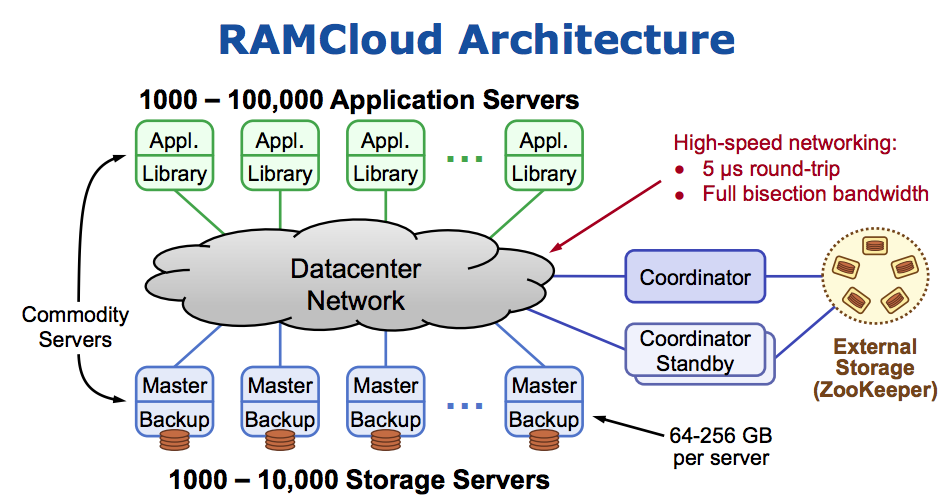
-
Each storage server contains a master and a backup. A central coordinator 1 manages the server pool and tablet configuration. Client applications run on separate machines and access RAMCloud using a client library that makes remote procedure calls.
- master: manages RAMCloud objects in its DRAM and services client requests
- backup: stores redundant copies of objects from other masters using its disk or flash memory
- coordinator: manages configuration information such as the network addresses of the storage servers and the locations of objects
- tablets: consecutive key ranges within a single table
-
Data model: object consists of [identifier(64b), version(64b), Blob(<=1MB)]
Durability and Availability
- Durability: 1 copy in DRAM; Backup copies on disk/flash: durability ~ free!
-
Availiability:
- Fast writes: Buffered Logging
- Fast crash recovery: Large-scale parallelism to reconstruct data (similar to MapReduce)
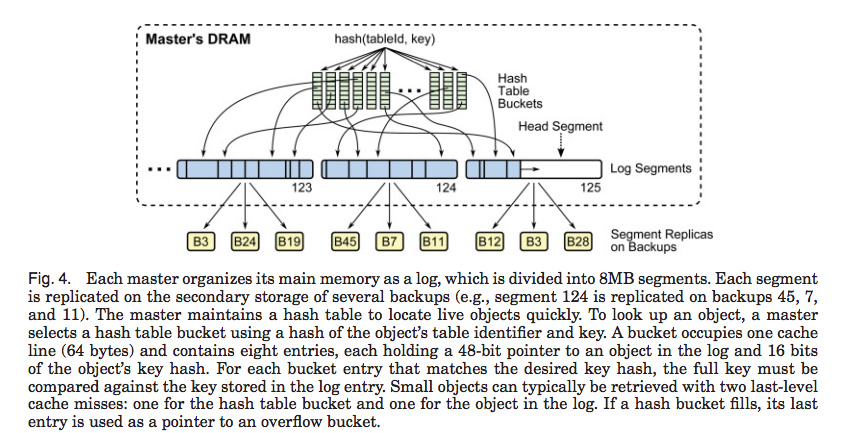
Buffered Logging
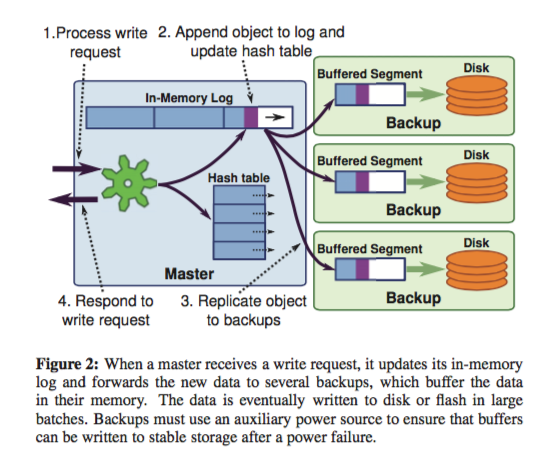
-
When a master receives a write requests, it updates its in-memory log and forwards the new data to several backups, which buffer the data in their memory. Master maintains a hash table to record locations of data objects. The data is eventually written to disk or flash in large batches. Backups must use an auxiliary power source to ensure that buffers can be written to stable storage after a power failure.
- No disk I/O during write requests
- Master’s memory also log-structured
- Log cleaning ~ generational garbage collection
- master’s log is divided into 8MB segments
- Hash table is used for quickly lookup object in log
Note
This part idea borrows from log-structured file system. Log structure in memory is thought to be interesting by Vijay.
Fast Recovery
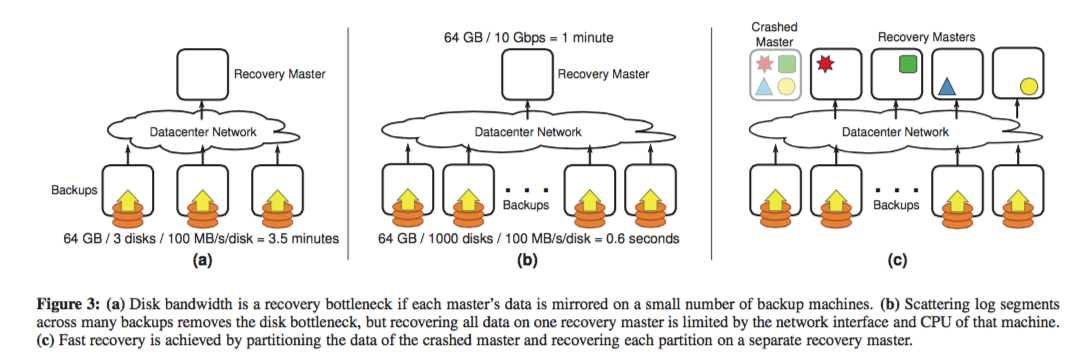
-
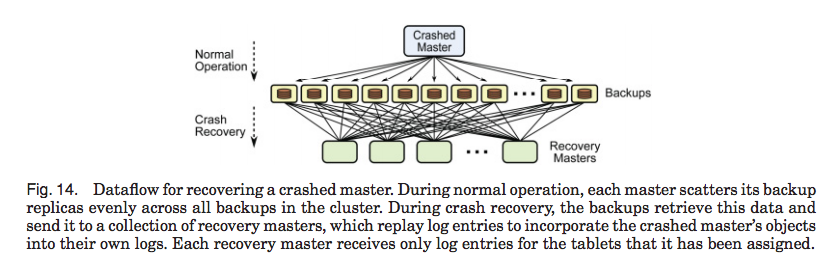
Three different recovery schemas:
- One recovery master, small backup servers (disk bandwidth bottleneck)
- One recovery master, large backup servers (network bandwidth bottleneck)
- Several recovery masters, large backup servers (good!)
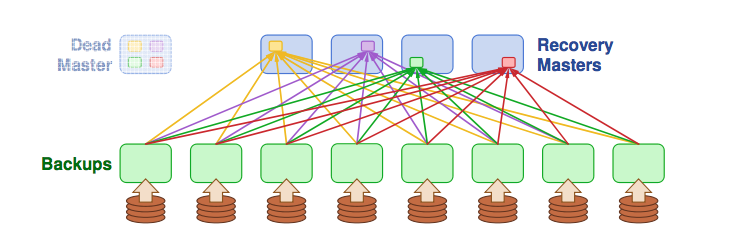
-
Divide each master’s data into partitions
- Partition and scatter log data to more backups randomly. So backup data can be read in parallel when the master crashed.
- Recover each partition on a separate recovery master
- Partitions based on tables & key ranges, not log segment
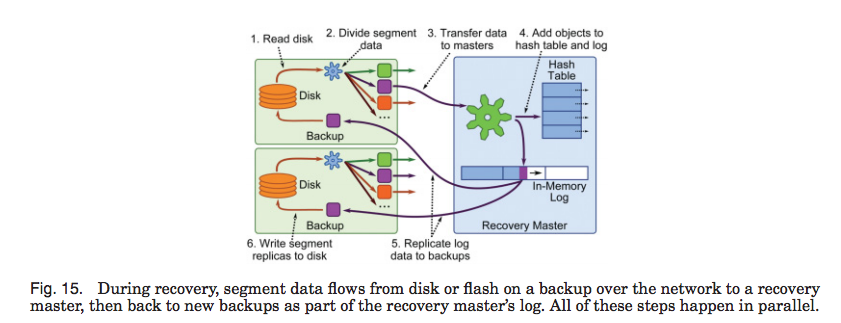
- Each backup divides its log data among recovery masters
-
Each mater computes the strategy to form partitions and upload the strategy to coordinator as will. Coordinator follows crashed master’s will to divide crashed master’s data into partitions and assign the recoverying work to recovery masters (see section 3.5.3)
Other interesting details
-
Each RAMCloud master decides independently where to place each replica, using a combination of randomization and refinement.
When a master needs to select a backup for a segment, it chooses several candidates at random from a list of all backups in the cluster. Then it selects the best candidate, using its knowledge of where it has already allocated segment replicas and information about the speed of each backup’s disk. The best backup is the one that can read its share of the master’s segment replicas most quickly from disk during recovery. A backup is rejected if it is in the same rack as the master or any other replica for the current segment. Once a backup has been selected, the master contacts that backup to reserve space for the segment. At this point the backup can reject the request if it is overloaded, in which case the master selects another candidate.
Note
Advantages of randomization + refinement:
- eliminate behavior: all masters choosing the same backups in a lock-step fashion
- provides a solution nearly as optimal as a centralized manager
- make segment distribution nearly uniform
- compensate for each machine difference: more powerful machine, high disk speed, more likely to be selected
- handles the entry of new backups gracefully: new machine, less workload, more likely to be selected
Remarks & Thoughts
Each segment is randomly shuffled to multiple backups and recovery is constructed in parallel, which reminds me of the MapReduce. Segments are distributed uniformly across backups, which mirrors chunking the data evenly in Map phase. The recovery from multiple recovery masters and each recovery master only done part of the whole need-to-be-recovered data, which reminds me of Reduce phase. Even Prof. John Ousterhout in the video thinks that MapReduce almost solve their problem.
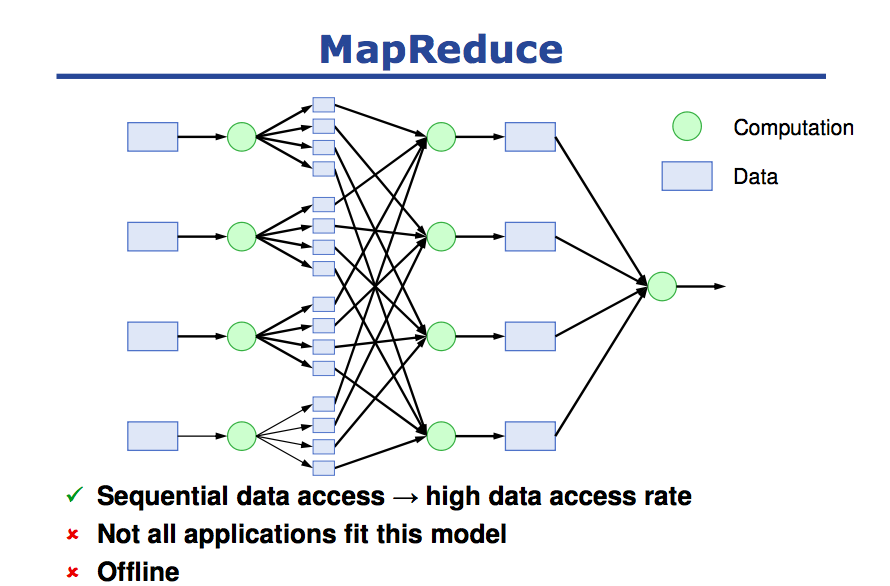
This finding is quite atonishing to me because MapReduce paper comes out in 2004 and RAMCloud comes out in 2011. If we take a slightly different angle to look at prior work, we may find something new. That’s provoking for me in terms of research.
Reference
- Fast Crash Recovery in RAMCloud, slides, video on paper, videos on details of paper.
- Tian Pan’s Blog on RAMCloud
- The RAMCloud Storage System
-
The coordinator will use ZooKeeper to store its configuration information, which consists of a list of active storage servers along with the tablets they manage. ZooKeeper本身是一个非常牢靠的记事本,用于记录一些概要信息。Hadoop依靠这个记事本来记录当前哪些节点正在用,哪些已掉线,哪些是备用等,以此来管理机群。 ↩