"PNUTS: Yahoo!’s Hosted Data Serving Platform"
Introduction
-
PNUTS system, a massive-scale, hosted database system to support Yahoo!’s web applications. Our focus is on data serving for web applications, rather than complex queries, e.g., offline analysis of web crawls.
-
PNUTS Goals
- Scalability
- Low latency, predictable latency
- Must handle attacks: flash crowds, denial of service
- High Availability
- Eventual Consistency
-
Design Purpose
- Our system is designed primarily for online serving workloads that consist mostly of queries that read and write single records or small groups of records
-
Application scenarios
- User database
- Social Applications
- Metadata for file systems
- Listings Management
- Session Data
-
PNUTS Overview
- Data Model and Features
- a simple relational model to users, and supports single-table scans with predicates
- Features:
- catter-gather operations
- a facility for asynchronous notification of clients
- a facility for bulk loading.
- Fault Tolerance
- employs redundancy at multiple levels (data, metadata, serving components, etc.) and leverages our consistency model to support highly-available reads and writes even after a failure or partition
- Pub-Sub Message System
- We chose pub/sub over other asynchronous protocols (such as gossip) because it can be optimized for geographically distant replicas and because replicas do not need to know the location of other replicas.
- Record-level Mastering
- To meet response-time goals, PNUTS cannot use write-all replication protocols that are employed by systems deployed in localized clusters (e.g. GFS)
- Not every read of the data necessarily needs to see the most current version. We have therefore chosen to make all high latency operations asynchronous, and to support record-level mastering.
- Asynchrony allows us to satisfy latency budget (50-100 ms) despite geographic distribution, while record-level mastering allows most requests, including writes, to be satisfied locally.
- Hosting
- PNUTS is a hosted, centrally-managed database service shared by multiple applications
- Significantly reduces application development time
- Consolidating multiple applications onto a single service allows us to amortize operations costs over multiple applications, and apply the same best practices to the data management of many different applications
- having a shared service allows us to keep resources (servers, disks, etc.) in reserve and quickly assign them to applications experiencing a sudden upsurge in popularity
- Data Model and Features
Data and Query Model
- Data is organized into tables of records with attributes
- Each row has a primary row
- Rows can have binary blobs
- The query language of PNUTS supports selection and projection from a single table
- single-table queries in fact provide very flexible access compared to distributed hash or ordered data stores, and present opportunities for future optimization by the system
- Queries:
- Point access: A user may update her own record, resulting in point access
- Range access: Another user may scan a set of friends in order by name, resulting in range access
- does not enforce constraints
- does not support complex ad hoc queries (joins, group-by, etc.)
Consistency Model
- per-record timeline consistency:
- all replicas of a given record apply all updates to the record in the same order
- same as per-object sequential consistency
- implementation:
- One of the replicas is designated as the master, independently for each record, and all updates to that record are forwarded to the master.
- the replica receiving the majority of write requests for a particular record becomes the master for that record
- API Calls
- Different levels of consistency guarantee
- Read-any: Returns a possibly stale version of the record
- Read-critical(required_version): Returns a version of the record that is strictly newer than, or the same as the \(required\_version\)
- Read-latest: Returns the latest copy of the record that reflects all writes that have succeeded
- Write: This call gives the same ACID guarantees as a transaction with a single write operation in it (e.g. blind writes, e.g., a user updating his status on his profile)
- Test-and-set-write(required_version): This call performs the requested write to the record if and only if the present version of the record is the same as required_version
- The test-and-set write ensures that two such concurrent increment transactions are properly serialized
- allows us to implement single-row transactions without any locks
- can provide serializability on a per-record basis
- no guarantees as to consistency for multi-record transactions
- if an application reads or writes the same record multiple times in the same “transaction,” the application must use record versions to validate its own reads and writes to ensure serializability for the “transaction.”
System Architecture
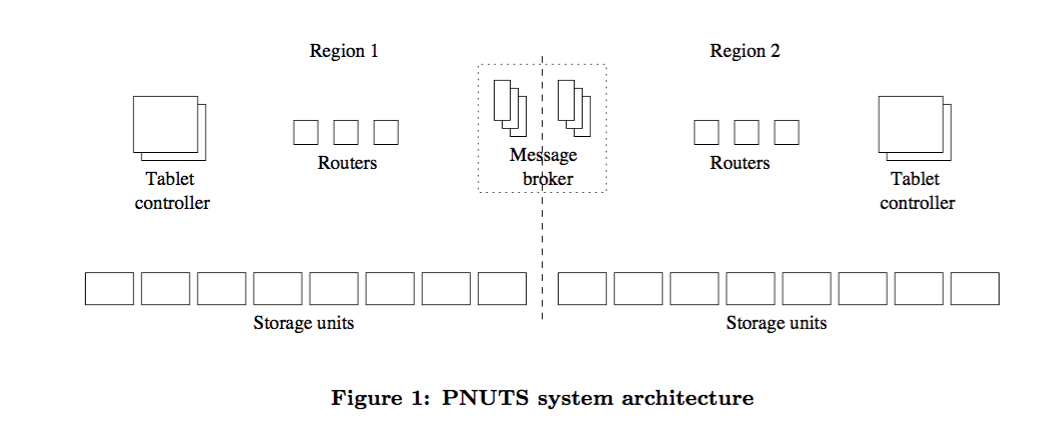
- The system is divided into regions, where each region contains a full complement of system components and a complete copy of each table
- Regions are typically, but not necessarily, ge- ographically distributed
- our system does not have a traditional database log or archive data
- use of a pub/sub mechanism for both reliability and replication
- we rely on the guaranteed delivery pub/sub mechanism to act as our redo log, replaying updates that are lost before being applied to disk due to failure
Data Storage and Retrieval
How the components within a region provide data storage and retrieval.
-
Data tables are horizontally partitioned into groups of records called tablets
- Tablets are scattered across many servers
- each tablet is stored on a single server within a region
- Each server has 100s-1000s of tablet
- Tablet size: 100s of MB or a few GBs
-
Three components in architecture are primarily responsible for managing and providing access to data tablets: the storage unit, the router, and the tablet controller.
- Storage Unit: get(), scan(), set()
- Updates are committed by first writing them to the message broker
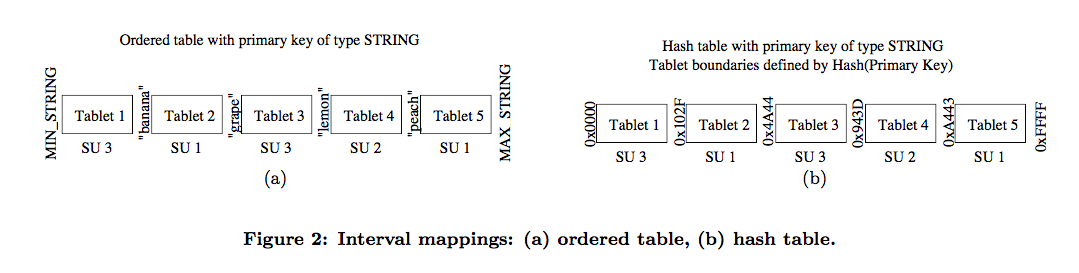
- Router: identifies which tablet and server contain data
- implemented using interval mapping
- Ordered data: key range sharded into tablets
- Unordered data: do the same with hash(key)
- Mapping information stored in memory
- Contains only a cached copy of the interval mapping (True source of mapping info: tablet controller)
- The tablet controller determines
- when it is time to move a tablet between storage units for load balancing or recovery
- when a large tablet must be split.
Replication and Consistency
We use the Yahoo! message broker, a publish/subscribe system developed at Yahoo!, both as our replacement for a redo log and as our replication mechanism.
YMB
-
Received messages are logged and replicated
- Data updates are considered “committed” when they have been published to YMB.
- At some point after being committed, the update will be asynchronously propagated to different regions and applied to their replicas.
-
When update has been applied to all replicas, log is pruned
- YMB servers are present in different regions
- Cross-region traffic is limited to YMB
- Messages are ordered within a YMB region
- Across regions, different ordering is possible
Consistency via YMB and mastership
- Per-record timeline consistency is provided by designating one copy of a record as the master, and directing all updates to the master copy.
- In this record-level mastering mechanism, mastership is assigned on a record-by-record basis, and different records in the same table can be mastered in different clusters.
- Update considered “committed” once YMB acks it
- A committed update may not be visible to other replicas
- Master replica for a given record is stored inside that record
- In order to enforce primary key constraints, we must send inserts of records with the same primary key to the same storage unit; this storage unit will arbitrate and decide which insert came first and reject the others. Thus, we have to designate one copy of each tablet as the tablet master, and send all inserts into a given tablet to the tablet master
- Tablet master can be different from record master
- Tablet master serializes updates to record
- Record master is the “true” copy of the data
- Update is considered “committed” once record master gets it
Recovery
- the tablet controller requests a copy from a particular remote replica (the “source tablet”)
- a “checkpoint message” is published to YMB, to ensure that any in-flight updates at the time the copy is initiated are applied to the source tablet
- the source tablet is copied to the destination region
Other Database System Functionality
Query Processing
- Scatter-gather engine is used
- Server has the engine, not the client
- Done to reduce network connections to the server
- Allows optimization over the whole scatter-gather call
- Range queries are broken up
- Clients keep a continuation object to continue the range query
Notifications
- User can subscribe to notifications
- Built on top of pub/sub architecture
- Accomplished by talking to the YMB
- Each tablet has a topic that user subscribe to
- Whenever tablet is updated or split, notifications can be sent out
Further Readings
Reference
- https://www.cs.utexas.edu/~vijay/cs380D-s18/feb8-pnuts-voting.pdf