"Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing"
Problem
How to design a system that support in-memory computation (with real-time interaction support) in large cluster efficiently with fault-tolerance?
- Prior systems are lack of abstraction for leveraging distributed memory (intermediate computing result reuse is problem: has to save and then read through storage system)
- Prior systems on data reuse do not have abstraction for general use (i.e., limited computatin pattern supported) and do not support real-time interaction (e.g., load data sets into memory and query them interactively)
System Design
Goal
- Provide distribued memory abstractions for clusters to support apps with working sets
-
Retain the attactive properties of MapReduce:
- Fault tolerance (for crashes & stragglers)
- Data locality
- Scalability
Resilient Distributed Datasets (RDD)
- Generality conjecture: Spark’s data flow + RDDs unifies many proposed cluster programming models (MapReduce, Dryad, SQL, Pregel (BSP), HaLoop (iterative MR), Continuous Bulk Processing)
-
An RDD is a read-only, partitioned, logical collection of records
- Need not be materialized, but rather contains information to rebuild a dataset from stable storage
-
Coarse-grained transformations (e.g., map, filter, join)
- efficiently fault-tolerant: logging the transformations used to build a dataset (its lineage) rather than the actual data
- vs. actions: operations that return a value to the application or export data to a storage system (e.g., count, collect, save)
-
Created through transformations on 1) data in storage 2) other RDDs
- User can specify which RDD to reuse and how to store it
- User can partition RDD across machines on a key
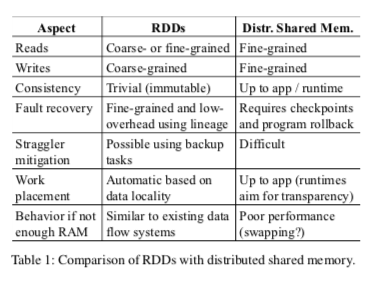
- vs. distributed shared memory (DSM)
- Can use persist method to indicate which RDDs the user want to reuse in future operations and specify persistence priority (e.g., which in-memory data should store to disk first) and persistence strategy (e.g., store RDD on disk instead of memory; replication)
- Target application: iterative algorithms and iterative data mining tools
- Limitation: not suitable for applications that make asynchronous fine-grained updates to shared state (e.g., storage system for a web app or an incremental web crawler)
-
Representing RDD by exposing information:
- parititions of datasets
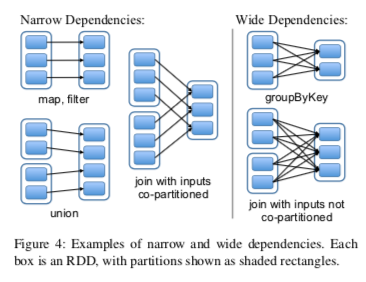
- dependencies on parent RDDs (narrow vs. wide) (see figure below)
- partition-based function for computing the dataset
- metadata on partitioning shceme and data placement