"Petal: Distributed Virtual Disks"
Problem
Design a distributed storage system that is easy-to-use and easy-to-administer.
-
Easy-to-use:
- Simple Interface
- availability / fault tolerance
- transparency
- consistency
-
Easy-to-administer:
- crash recovery (no manual needed)
- scability (scale up with the workloads without performance degration)
- add / remove nodes
- load balancing
- monitoring
System design
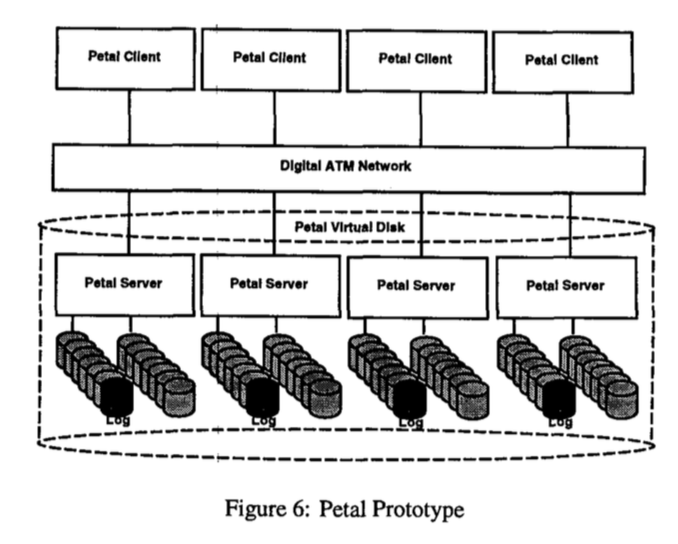
- Petal consists of a collection of network-connected servers that cooperatively manage a pool of physical disks
Note
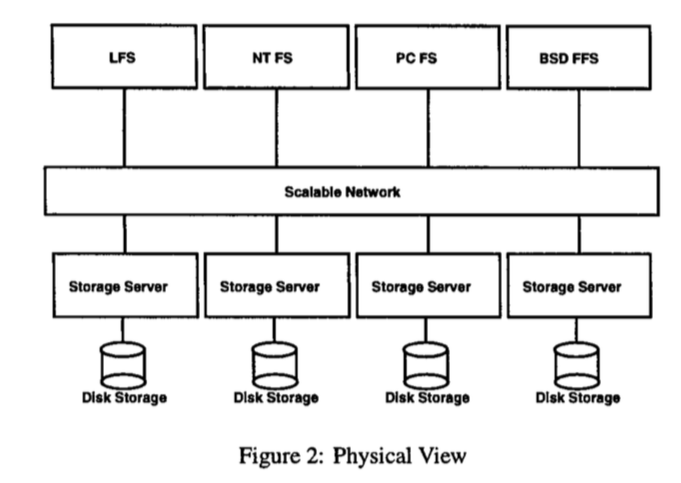
Petal is different from distributed file system (NFS) in the sense that clients in NFS can directly access the server physical disks. However, Petal hides the physical resources through the layer of abstraction. The benefits of this abstraction: - scale to a large size and reliable data storage over in long run - support heterogeneous clients and client applications (e.g., different file systems) (Figure 2)
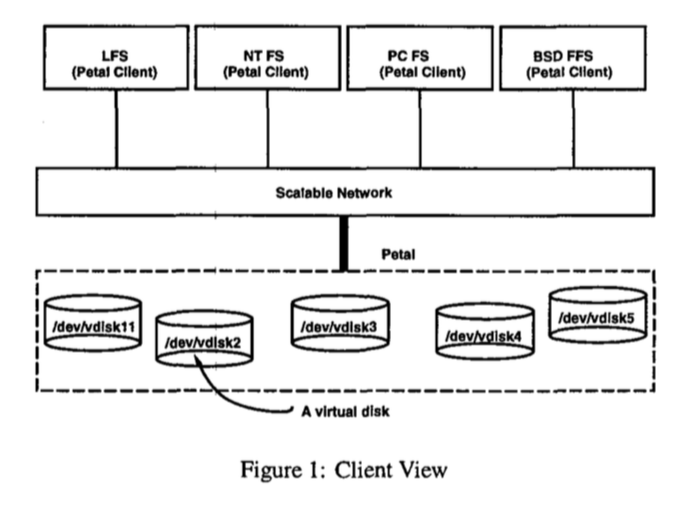
- Clients (FS or DB) view Petal as a collection of virtual disks (Figure 1)
- Disk-like Interface: data are read and written to Petal virtual disks in blocks (i.e., the basic tranfer unit) through RPC
-
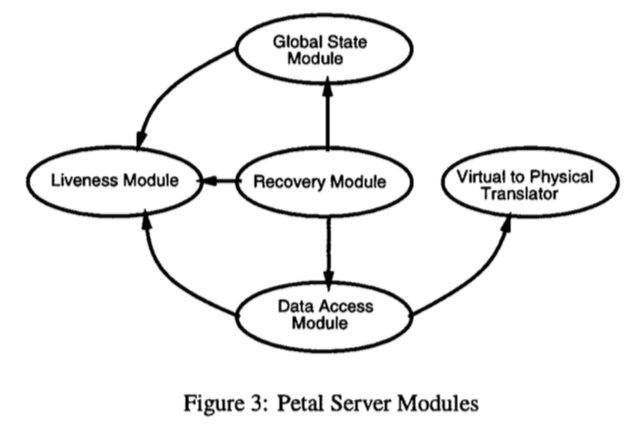
Software modules:
- liveness module:
- ensures that all servers in the system will agree on the operational status (running or crashed) of each other
- majority consensus (Paxos) + heatbeat
- global state module:
- include information: current members of system + currently supported virtual disks
- consistently maintain information -> Paxos
- liveness module:
-
Virtual disk address -> physical disk address:
- virtual disk address form:
- virtual disk identifier -> global map identifier (via. virtual disk directory)
- global map identifier decides the server for translating offset
- global map identifier & offset -> disk-identifier, disk-offset (via. phyiscal map on each server)
- virtual disk address form:
Note
Separation of the translation data structures into global and local physical maps: - keep bulk of mapping information local (minimizes the information kept globally, which is replicated and thus hard to update)
-
Global map:
- One global map per virtual disk that specifies the tuple of servers spanned by the virtual disk
- immutable -> new global map if change virtual disk’s tuple of server / redundancy scheme
-
Backup:
- copy-on-write to create exact copy of a virtual disk at a specified point in time
- Use epoch-number as version number
- Create a snapshot consistent with client application level requires pauseing the application
- Can also use “crash-consistent” snapshot and later recovered by the application-specific recovery protocol
-
Add server:
- add to the membership of the Petal
- adjust liveness module to incorporate new server
- virtual disk reconfiguration (reconfigure existing virtual disks to use new resources -> data redistribution)
-
Virtual disk reconfiguration (data redistribution):
- data redistribution can take hours to finish (won’t compete network & disk traffic with write/read serving)
- Basic steps:
- create a new global map with redundancy scheme + server mapping
- change all virtual disk directory entries that refer to the old global map to refer to the new one
- redistribute data to servers according to new global map
- start with the most recent epoch that have not yet been moved (not return old data when READ)
- need to read/write during redistribution:
- READ: try the new global map first, then the old global map
- WRITE: use new global map
- Refinement:
- don’t need to change server mapping for an entire virtual disk before any data is moved (-> READ miss given new global map)
- sol:
- break virtual disk’s address into: old, new, fenced
- Requests to old/new use old/new global maps
- Use “Basic steps” for fenced only
- Once we have relocated everything in the fenced region, it becomes new region and we fence another part of the old region
- tricks:
- keep the relative size of the fenced region small
- construct fenced region using small non-contiguous ranges distributed throughout the virtual disk (not single contiguous region b/c fenced region may be heavily used)
-
Data access and recovery:
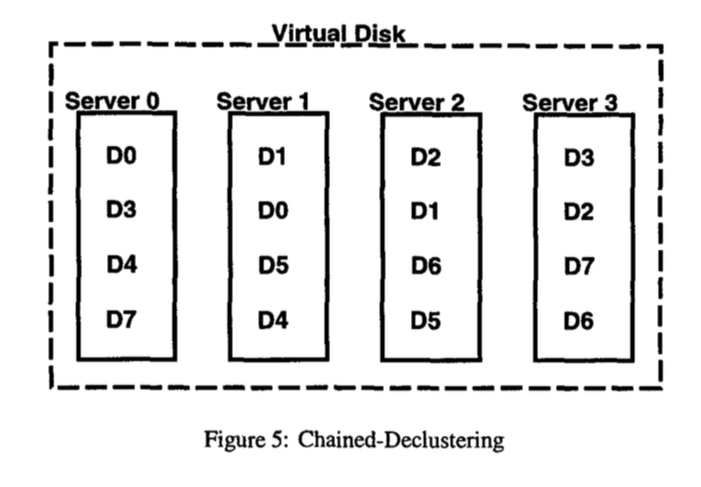
- Use chained-declustered data access and recovery modules (chained-declustering):
- Two copies of each block of data are always stored on neighboring servers
- Server 1 fails, servers 0 and 2 will share server 1’s real load; server 3 will not have load increase
- Can offload load to a server to neighboring servers
- similar to consistent hashing
- Two copies of each block of data are always stored on neighboring servers
- Dynamic load balancing scheme:
- each client keep tracks of the number of requests it has pending at each server and always sends read requests to the server with the short queue length
- Works for most of requests are from a few clients (not for many clients with occassional requests)
- Tolerate site failures:
- all the even-numbered servers at one site and all the odd-numbered servers at another site (less reliable since data on a given server is replicate on neighboring only)
- one of two copies of each data block is denoted the primary. Rest are secondary.
- READ:
- Read from either primary or secondary
- Clients retry on failure
- WRITE:
- Use primary always
- Mask the data as busy. Simultaneously sends write requests to its local copy and the secondary copy. When both requests complete, the busy bit is cleared and the client that issued the request is sent a status code indicating the success or failure of the operation.
- Optimization:
- write-ahead-logging with group commits (batch the busy bits update)
- cache the busy bits (avoid disk I/O to set busy bits)
- Primary fail:
- the secondary marks the data element as stale on stable storage before writing it to its local disk. The server containing the primary copy will eventually have to bring all data elements marked stale up-to-date during its recovery process.
- Use chained-declustered data access and recovery modules (chained-declustering):
-
Petal’s limitation:
- High requirement to the network (use digital ATM Network)
- Petal’s use of the virtual disk abstraction adds an additional level of overhead, and can prevent application-specific disk optimizations that rely on careful placement of data.