"MapReduce: Simplified Data Processing on Large Clusters"
Problem
Design a simple-to-use (no exposure of messy details of parallelization, fault-tolerance, data distribution and load balancing to user)programming model (i.e., abstraction interface) that can process large amount of data in a reasonable amount of time.
Design assumptions
- Large clusters of commodity PCs connected together with switched Ethernet
- 2-4GB memory Linux machine
- 100 MB/s or 1 GB/s network bandwidth
- machine failures are common
- unreliable hardware
- distributed file system (use replication to provide availability and reliability)
- scheduler to schedule tasks to a set of available machines within a cluster
Programming model
The computation takes a set of input key/value pairs, and produces a set of output key/value pairs
- Map, written by the user, takes an input pair and produces a set of intermediate key/value pairs
- The MapReduce library groups together all intermediate values associated with the same intermediate key I and passes them to the Reduce function.
- The Reduce function, also written by the user, accepts an intermediate key I and a set of values for that key. It merges together these values to form a possibly smaller set of values.
Example:
Count of URL Access Frequency: The map function processes logs of web page requests and outputs ⟨URL, 1⟩. The reduce function adds together all values for the same URL and emits a ⟨URL, total count⟩ pair.
Execution
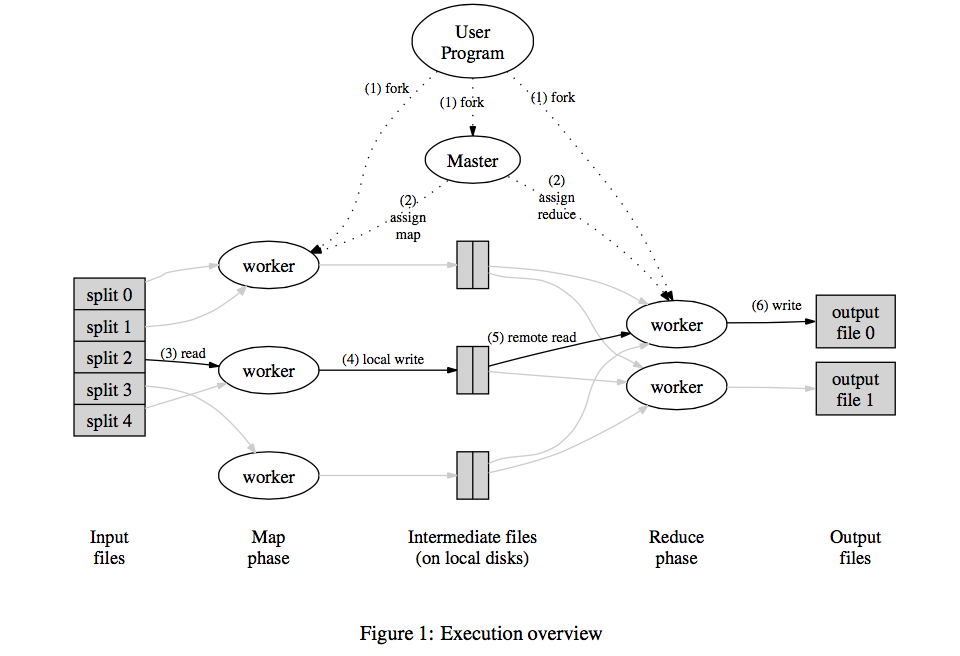
-
The Map invocations are distributed across multiple machines by automatically partitioning the input data into a set of M splits.
-
Reduce invocations are distributed by partitioning the intermediate key space into R pieces using a partitioning function (e.g., \(hash(key) \textbf{ mod } R\))
-
Execution Process:
-
The MapReduce library in the user program first splits the input files into M pieces. It then starts up many copies of the program on a cluster of machines.
-
One copy of the program is called Master. The rest are workers that are assigned work by the master. The master picks idle workers and assigns each one a map task or a reduce task.
-
Worker assigned map task do Map job and buffer the output in memory
-
Periodically, the buffered pairs are written to local disk, partitioned into R regions by the partitioning function. The locations of these buffered pairs on the local disk are passed back to the master, who is responsible for forwarding these locations to the reduce workers.
-
Reduce worker reads the buffered data from the local disks of the map workers using RPC. Perform Group by on the immediate keys.
-
Reduce worker do reduce job and append the output to a final output file of this reduce partition.
-
All Map and Reduce tasks are done, the master wakes up the user program and return the program control.
-
-
Map & Reduce tasks have three states: idle, in-progress, or completed
System design
-
In the execution, the output are buffered in memory and write to disk in batch to reduce disk I/O overhead.
-
Fault tolerance:
- Master pings every worker periodically to detect worker failure
- Completed map tasks are re-executed on a failure (intermediate output are stored in local disk and thus inaccessible)
- Completed reduce tasks are not re-executed on failures (results are in GFS, which are replicated already)
- Master Failure:
- Periodic checkpoints
- Aborts MapReduce computation if master fails (current implementation)
-
Sequential consistency: when Map and Reduce operation is determinstic to the input file, the distributed execution output is the same as the non-faulting sequential execution of the entire program:
- Atomic commits of map and reduce task outputs
-
Trade-off on each task size vs. M or R:
- \(O(M + R)\) scheduling descisions
- \(O(M \dot R)\) states in memory
- small task size, large M or R given the input job size is fixed
- Large task size, small M or R given the input job size is fixed (make parallel meaningless)
-
Handle “straggler”:
- “Straggler”: a machine that takes an unusually long time to complete one of the last few map or reduce tasks in the computation.
- When a MapReduce operation is close to completion, the master schedules backup executions of the remaining in-progress tasks. The task is marked as completed whenever either the primary or the backup execution completes.
-
Locality: schedule map tasks to the machines where the replicas of the input data is stored (input data can read locally and consume no network bandwidth). This is saying of “push program to the data node”.
-
Refinements:
-
Use a partition function on the intermediate keys such that, for example, all URLs from the same host to end up in the same output file. For ease-to-use from the application layer.
-
within a given partition, the intermediate key/value pairs are processed in increasing key order. For efficient loopup in the output file.
-
Optional Combiner function that does partial merging of the intermediate keys on the map task worker before the data is sent over the network to the reduce worker (reduce network usage)
-
the MapReduce library detects which records cause deterministic crashes and skips these records in order to make forward progress.
-
Remarks
- Re-execution to provide fault tolearance is a commonly-seen technique (used in Spark as well) in “Big-data” paper
- Spawn multiple same tasks to handle “straggler” problem is also common
- Locality is a nice trick to use to reduce bandwidth usage
- Stonebraker’s video on database research mentions that MapReduce is no longer used in Google. We as researcher should play critical on the papers produced by “whales” and not treat them as the golden standard (we do because we lose connection to industry). Totally different topic.
- I don’t think MapReduce is a database work. I feel it just some framework that allows Google to get their job done (If you think about Jeff Dean’s major focus is on programming languages not database). Unlike database, the framework is hard to generalize.
- Spot Remzi’s papers in the reference section. Neat!